The incident!
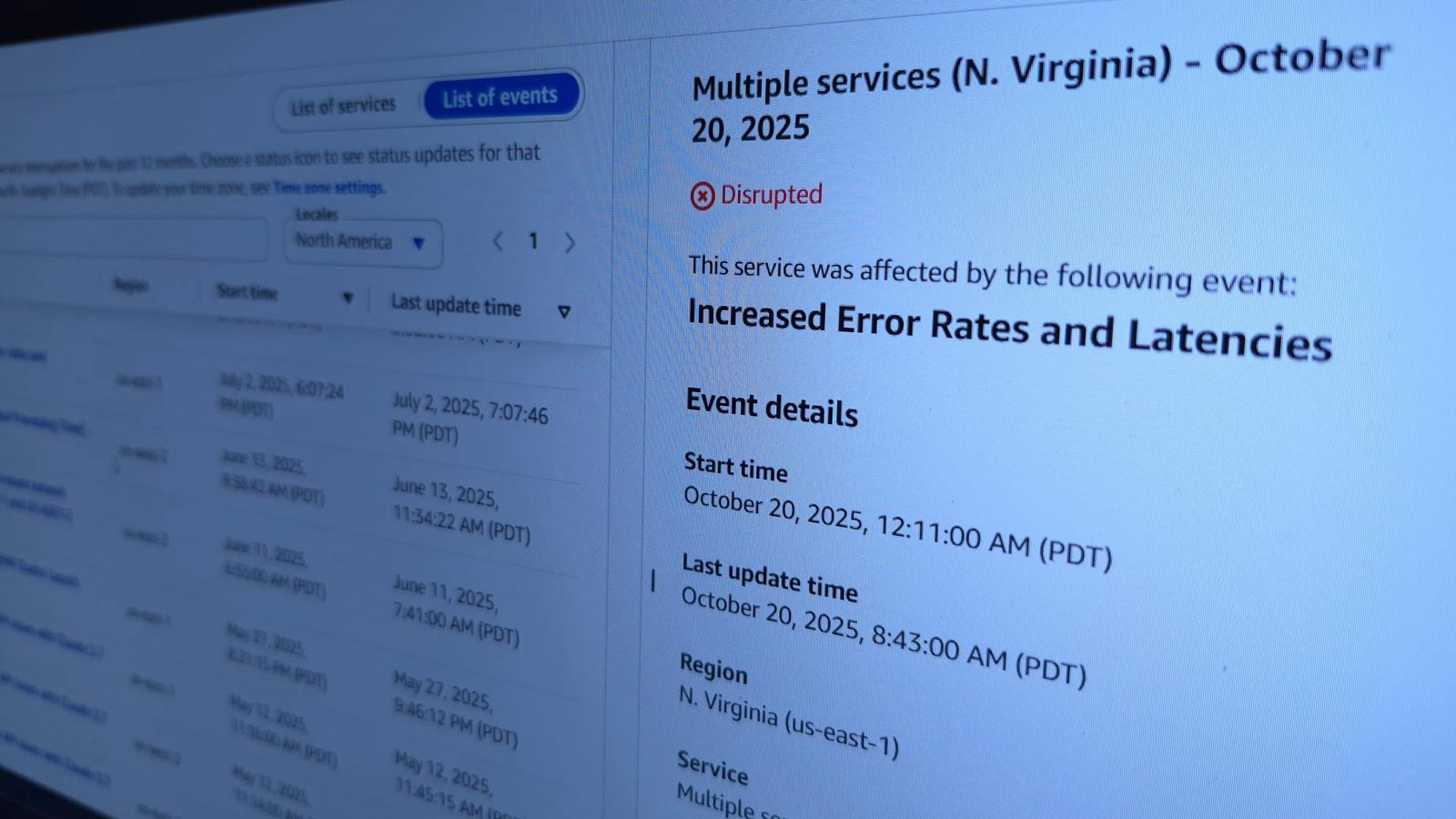
On 20 October 2025, at 07:11 AM GMT, Amazon Web Services (AWS) experienced a major disruption in its US-East (Virginia) region — one of its oldest and largest data centres. The incident triggered a chain reaction across the internet, temporarily taking down or slowing thousands of websites, mobile applications, and cloud-hosted services around the world.
Even technology giants such as WhatsApp, Zoom, Slack, Snapchat, Pinterest, and Apple TV were affected, revealing just how dependent the global digital ecosystem has become on AWS infrastructure.
What happened?
Initial reports indicate that the outage originated from a problem with AWS’s Domain Name System (DNS).
In simple terms, whilst the data and applications themselves remained intact, the DNS servers — responsible for directing user requests to the correct destination — stopped resolving properly.
As a result, users’ devices did not know where to locate the services, causing widespread downtime.
The outage lasted for roughly 12 hours, affecting everything from communication platforms to streaming services and causing significant financial and operational impact across multiple industries.
You can read more about the incident here: BBC News report
The key takeaway: even the giants can fail
This event is a clear reminder that no provider is immune — not even AWS, the world’s largest cloud service provider.
Organisations that rely entirely on a single platform for hosting, data, and DNS are effectively placing all their eggs in one basket.
Outages like this highlight the need for resilient architecture, robust backup strategies, and disaster recovery (DR) planning to safeguard against the unexpected.
How to protect your business from cloud service disruptions
Here are some practical, security-focused measures to reduce exposure and improve resilience.
- Maintain remote backups
Always store off-site backups of your applications, configurations, and databases on a platform independent of your main provider.
For example, if your production servers are hosted on AWS, consider maintaining backups on Microsoft Azure, Google Cloud, or a secure on-premises server.
The frequency of backups should reflect your operational needs — for instance, daily incremental backups and weekly full snapshots. - Avoid over-reliance on proprietary services
Whilst AWS offers scale and convenience, some of its services (such as Lambda, DynamoDB, or Route 53) can be difficult to replicate elsewhere.
Design your applications using cloud-agnostic technologies — for example, Docker containers, PostgreSQL, or standard APIs — to allow for rapid migration should your main provider experience downtime. - Conduct annual disaster recovery (DR) tests
A disaster recovery plan is only as effective as its last test.
At least once a year, carry out a full disaster recovery simulation, restoring your application from backups on an alternative platform or region.
This confirms that your recovery procedures work and that your team is prepared to act quickly in a real-world scenario. - Review your business interruption insurance
Not all insurance policies automatically cover losses caused by cloud outages or third-party service failures.
Confirm that your business interruption insurance explicitly includes cloud service disruptions, data unavailability, and downtime-related loss of revenue. - Diversify critical dependencies
If your organisation relies on email, communications, or file storage hosted by a single vendor, consider using redundant providers or hybrid setups.
For example, if AWS handles your main workloads, host your DNS with Cloudflare or Google Domains.
Similarly, replicate critical logs and analytics data to a secondary platform.
Final thoughts
The AWS Virginia outage is a timely reminder that resilience is not a luxury — it is a core security principle.
Cloud technology offers enormous advantages, but true reliability comes from distributed risk, regular testing, and strategic redundancy.
Whether you are a start-up or an established business, ensure that your infrastructure is not only fast and scalable but also fault-tolerant, recoverable, and ready for anything.
About sapnagroup
At sapnagroup, we help businesses build secure, resilient, and high-performance infrastructures across web and mobile platforms.
With decades of experience in server management, cloud architecture, and information security, our team ensures your digital assets remain safe, compliant, and always available — even when the unexpected happens.
If you would like to strengthen your disaster recovery or security posture, contact us today to discover how we can help you design for reliability, not just performance.